BIP3D: Bridging 2D Images and 3D Perception for Embodied Intelligence¶
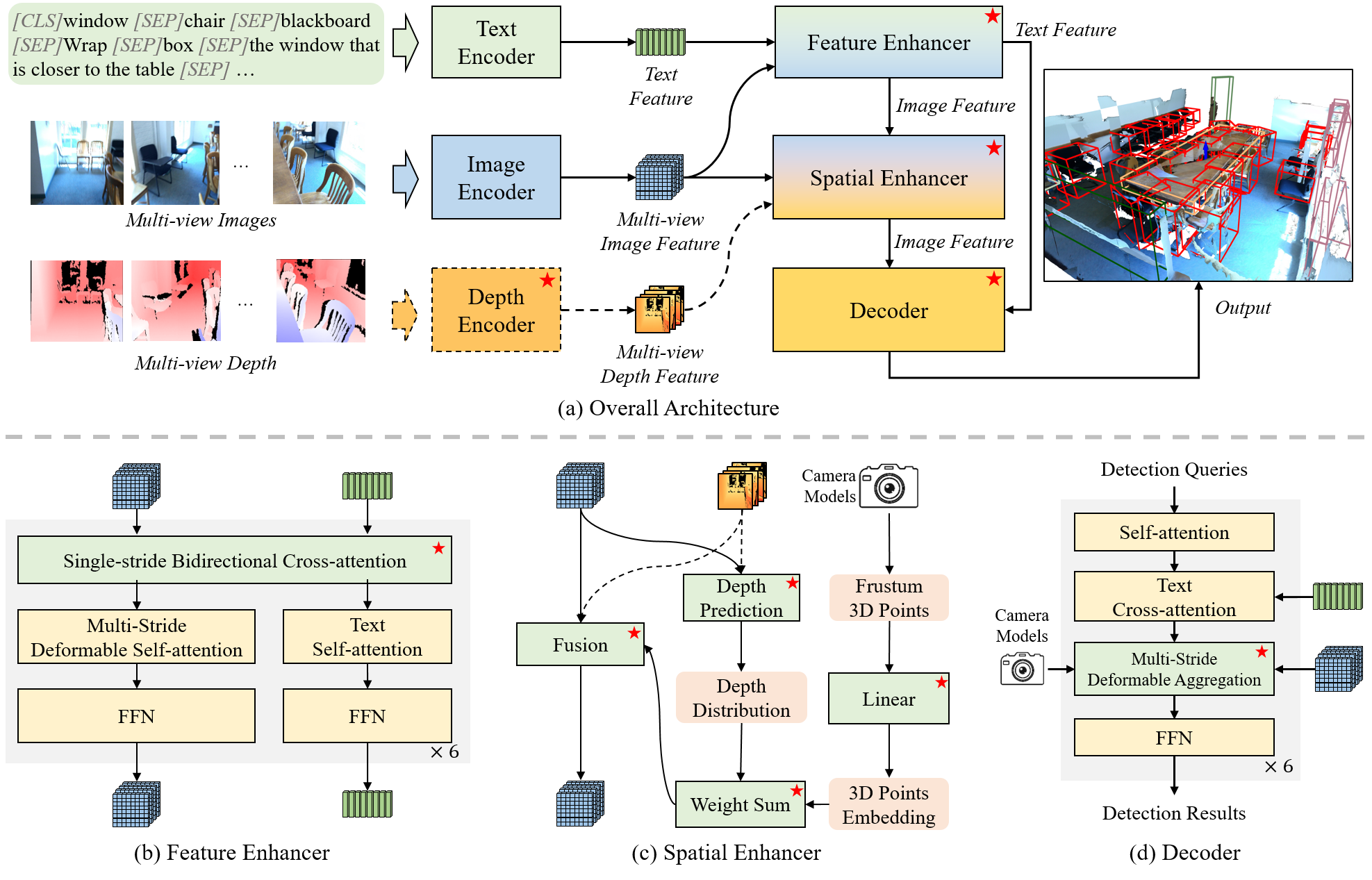
Introduction¶
In embodied intelligence systems, a key component is the 3D perception algorithm, which enables agents to understand their surrounding environments. Previous algorithms primarily rely on point clouds, which, despite offering precise geometric information, still constrain perception performance due to inherent sparsity, noise, and data scarcity.
BIP3D is a novel image-centric 3D perception model that leverages expressive image features with explicit 3D position encoding to overcome the limitations of point-centric methods. Specifically, BIP3D utilizes pre-trained 2D vision foundation models to enhance semantic understanding and introduces a spatial enhancer module to improve spatial understanding. Together, these modules enable BIP3D to achieve multi-view, multi-modal feature fusion and end-to-end 3D perception.
BIP3D demonstrates exceptionally superior 3D perception capabilities, achieving state-of-the-art performance in both 3D detection and grounding tasks on public datasets. It is capable of handling a variety of scenarios, delivering robust perception capabilities in dense environments, as well as for small and oversized targets. Moreover, BIP3D exhibits excellent generalization across both intrinsic and extrinsic camera parameters, supporting multiple camera types.
We highly recommend visiting the BIP3D Project Page for visual demonstrations and further details.
Key Features¶
Image-Centric Approach: Leverages rich 2D image features as the primary input, enhanced with 3D position encoding.
Foundation Model Integration: Utilizes pre-trained 2D vision foundation models for strong semantic understanding.
Spatial Enhancer Module: Improves spatial understanding critical for 3D perception.
Multi-View & Multi-Modal Fusion: Effectively fuses information from multiple camera views and potentially other modalities.
End-to-End 3D Perception: Offers a complete pipeline from input to 3D detection and grounding.
State-of-the-Art Performance: Achieves leading results on public benchmarks for 3D detection and grounding.
Robustness & Generalization: Performs well in diverse and challenging scenarios, including dense environments, varied target sizes, and different camera setups.
Using the pretrained model¶
You can easily load and use pre-trained BIP3D models.
import torch
from robo_orchard_lab.models import ModelMixin
# Load the pre-trained BIP3D Tiny Detection model from Hugging Face Hub
model: torch.nn.Module = ModelMixin.load_model("hf://HorizonRobotics/BIP3D_Tiny_Det")
Resources¶
Project Homepage: BIP3D Homepage Includes detailed explanations, visualizations, videos, and links to related resources.
Paper (arXiv): BIP3D: Bridging 2D Images and 3D Perception for Embodied Intelligence
Hugging Face Hub: BIP3D Hub Provides access to pre-trained model checkpoints, model cards, and example usage.
Performance¶
BIP3D has demonstrated state-of-the-art performance on various 3D perception tasks. Below are summarized results on key benchmarks. For a comprehensive analysis, including more detailed metrics, benchmark comparisons, and ablation studies, please refer to the official paper and the project homepage. Pre-trained model checkpoints corresponding to these results can often be found on our Hugging Face Hub page.
Citation¶
If you find BIP3D useful in your research, please consider citing the following paper:
@article{lin2024bip3d,
title={BIP3D: Bridging 2D Images and 3D Perception for Embodied Intelligence},
author={Lin, Xuewu and Lin, Tianwei and Huang, Lichao and Xie, Hongyu and Su, Zhizhong},
journal={arXiv preprint arXiv:2411.14869},
year={2024}
}