SEM: Enhancing Spatial Understanding for Robust Robot Manipulation¶
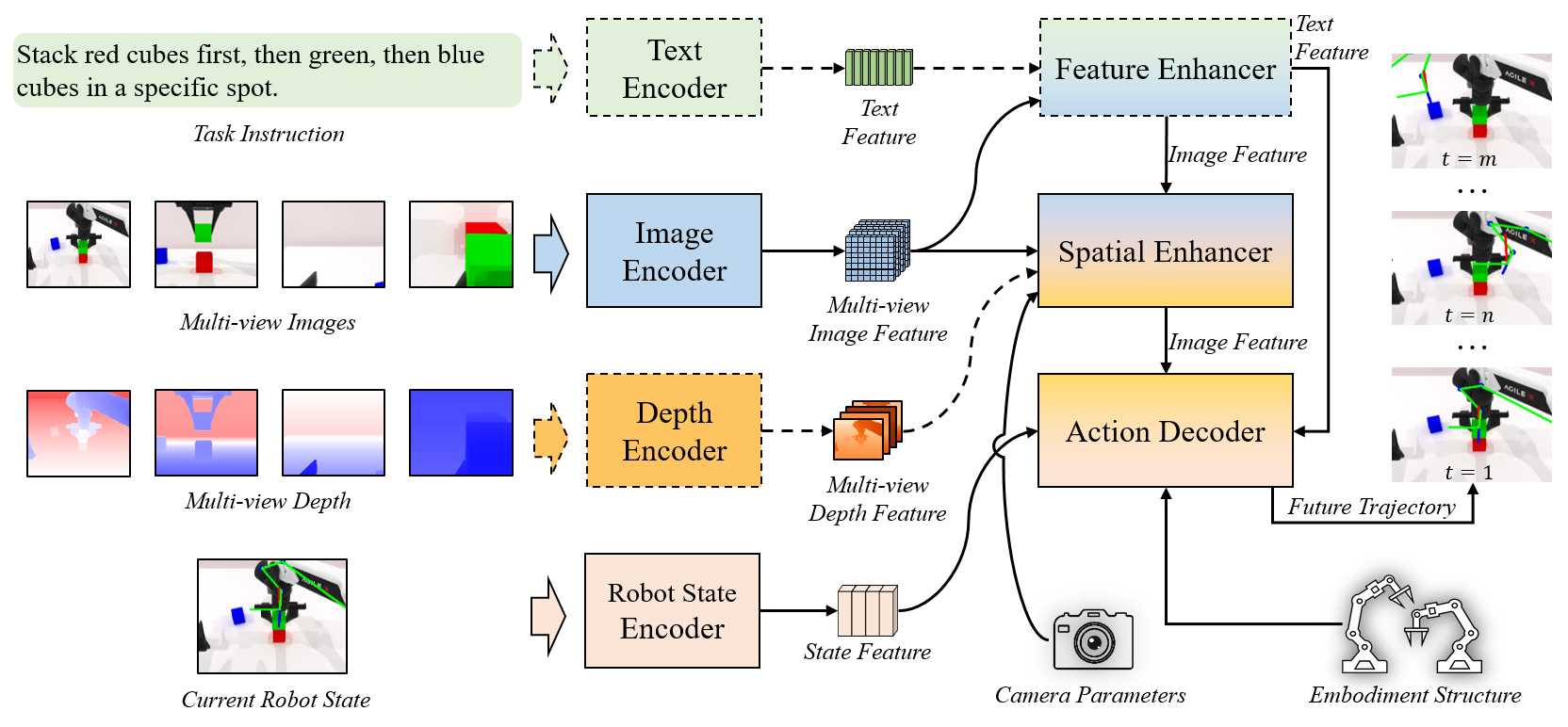
Introduction¶
Robust robot manipulation in diverse real-world environments hinges on a core capability: spatial understanding, the ability to perceive and reason about 3D geometry, object relations, and the robot’s own embodiment. While recent diffusion-based policy models have demonstrated strong generative capacity for action modeling, their effectiveness remains limited by perceptual bottlenecks:
a reliance on 2D visual encoders with limited spatial reasoning,
insufficient modeling of the robot’s internal structure beyond end-effector trajectories.
In this work, we propose SEM (Spatial Enhanced Manipulation model), a novel diffusion-based policy framework that explicitly enhances spatial understanding through two complementary perceptual modules. First, we introduce a 3D spatial enhancer that lifts multi-view 2D image features into a unified 3D representation by leveraging camera geometry and depth observations. This module enables fine-grained spatial reasoning while preserving the semantic richness of 2D vision backbones, effectively resolving the spatial ambiguities inherent in purely 2D encodings. Second, we propose a joint-centric robot state encoder that models the robot’s kinematic structure as a graph of interconnected joints. By predicting distributions over full joint trajectories, not just end-effector poses, and applying graph attention to capture joint dependencies, this module enhances embodiment-aware understanding and enables finer-grained control.
By integrating these two modules into a unified diffusion transformer, SEM enhances action generation capabilities, improving both spatial understanding of the external environment and internal robot embodiment, resulting in more robust, generalizable, and precise manipulation.
Key Features¶
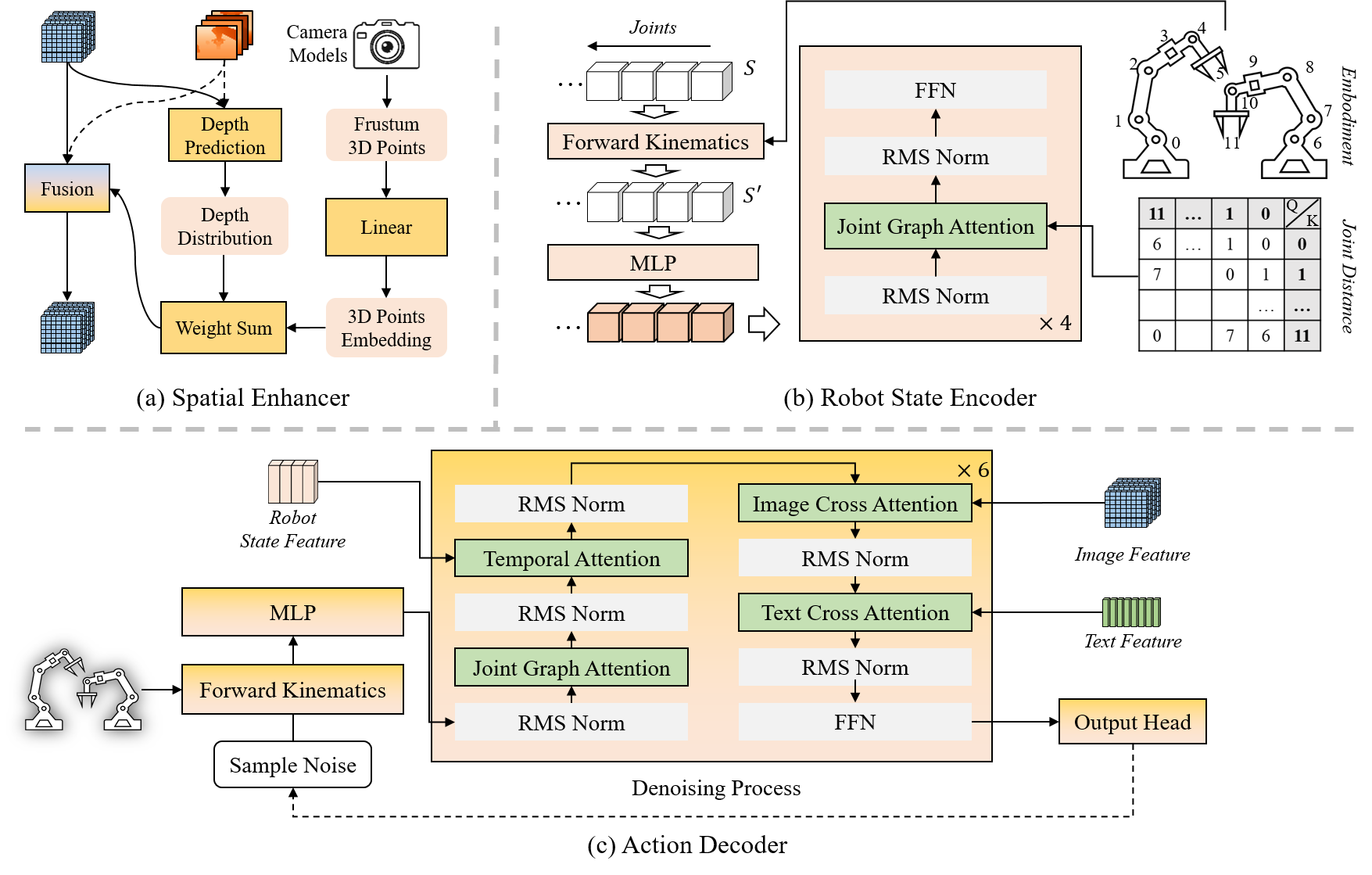
Spatial Enhancer:
Elevates multi-view 2D image features into a unified 3D representation using camera geometry and depth observations.
Enables fine-grained spatial reasoning while preserving the semantic richness of 2D vision backbones.
Resolves spatial ambiguities inherent in purely 2D encodings.
Joint-Centric Robot State Encoder:
Models the robot’s kinematic structure as a graph of interconnected joints.
Predicts distributions over full joint trajectories, not just end-effector poses.
Applies graph attention to capture joint dependencies, enhancing embodiment-aware understanding and enabling finer-grained control.
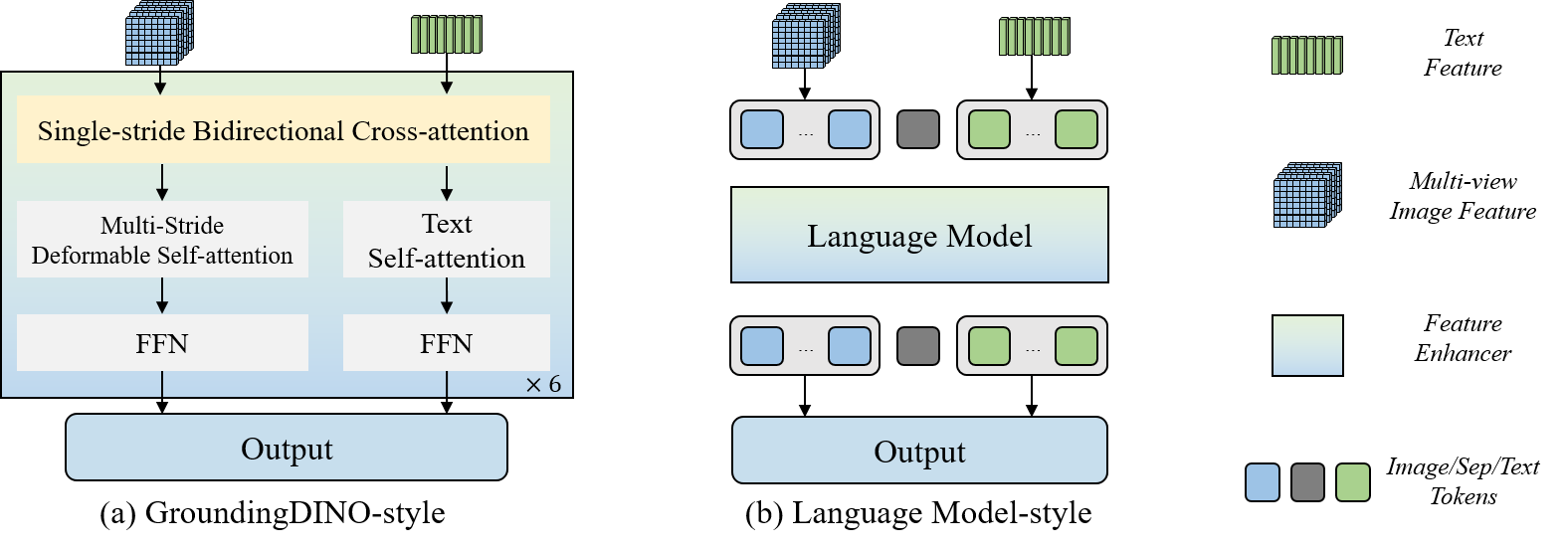
Feature Enhancer:
Facilitates cross-modal fusion and alignment of text and image features, emphasizing task-relevant regions.
Offers two implementations: GroundingDINO-style enhancer and language model-style enhancer.
Action Decoder:
Employs a diffusion transformer to predict future trajectories from aggregated features.
Includes additional cross-attention modules for robot state, image, and text features.
Temporal cross-attention operates in a causal manner to ensure unidirectional flow along the time axis.
Resources¶
Citation¶
If you find SEM useful in your research, please consider citing the following paper:
@article{lin2025sem,
title={SEM: Enhancing Spatial Understanding for Robust Robot Manipulation},
author={Lin, Xuewu and Lin, Tianwei and Huang, Lichao and Xie, Hongyu and Jin, Yiwei and Li, Keyu and Su, Zhizhong},
journal={arXiv preprint arXiv:2505.16196},
year={2025}
}